IndexRecordContainer
An IndexRecordContainer integrates an Entity into the index-based search. Each Entity may define only one IndexRecordContainer with configMode = INDEXGROUP_DEFINITION. This container maps the output of a data query to defined index fields. The order of fields in indexFieldMappings must exactly match the result structure returned by the configured query or subprocess.
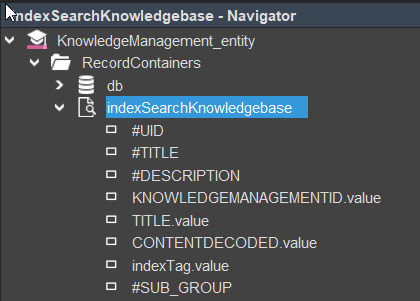
This documentation uses the IndexRecordContainer indexSearchKnowledgebase from the ADITO xRM project as a representative example. It is defined within the entity KnowledgeManagement_entity (module knowledge-management).
Properties
Field Mapping
indexFieldMappings
With indexFieldMappings, you map EntityFields to the result columns of the query or subProcess. The order must exactly match the returned data structure to ensure correct assignment.
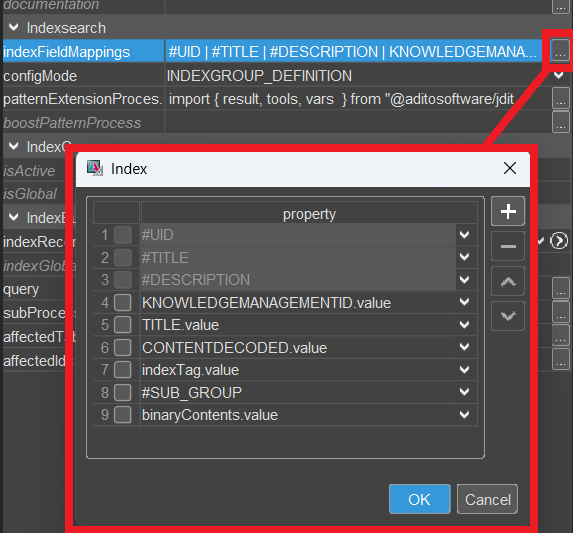
The first three fields are always prefilled and readonly, as they must come first:
- #UID: Unique identifier for the dataset (e.g., CONTACTID, PERSONID). Used for internal mapping, not shown in the UI.
- #TITLE: Title of the search result. Shown as the first line in the result dialog and in the"TITLE" column for further results.
- #DESCRIPTION: Description text for the search result. Shown as the second line in the result dialog and in the "DESCRIPTION" column for further results.
These three fields are mandatory.
Optional fields:
- #DATE: Date or timestamp for the index document (e.g.,
DATE_NEW,DATE_EDIT). Used for sorting and ranking, must be a UTC timestamp or string (YYYY-MM-DDThh:mm:ssZ). For more details, see propertyindexsearchBoostLatestDocuments. - #SUB_GROUP: Allows grouping of search results within one IndexRecordContainer for further filtering (e.g., documentation, news, user entries).
- #LOCATION: For spatial search; stores coordinates as
"lat, long"(e.g.,"48.47355270385742,12.257427215576172"). - #INDEX_GROUP: System field to override the index group/context during indexing (rarely used).
patternExtensionProcess
With patternExtensionProcess, you can programmatically add search patterns to the user's search query, typically to restrict results based on external conditions (e.g., user roles or flags). The user does not see these extensions. Patterns must follow Lucene / Solr syntax.
configMode
The configMode property determines the configuration mode for the IndexRecordContainer. There are two modes:
INDEXGROUP_DEFINITION
Defines a new index group ("Category" in the web client). Only one IndexRecordContainer per Entity/Context can use this mode.
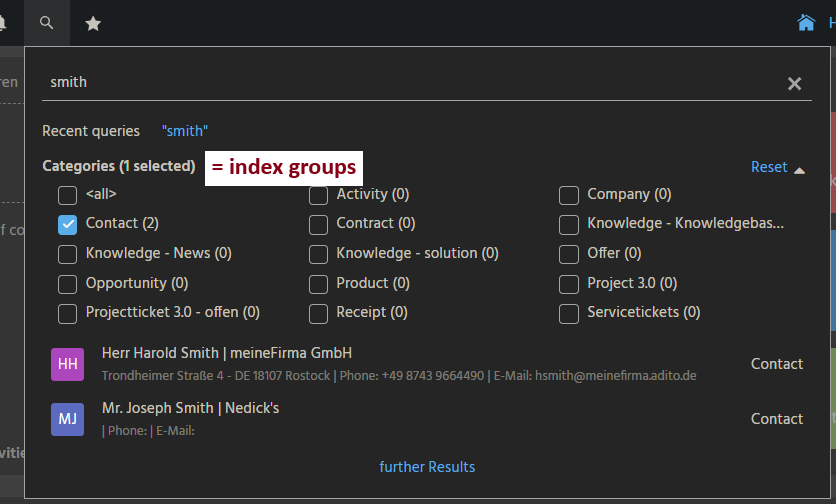
Key properties:
- isActive: Enables or disables the index group. If disabled, the index group is not built or searchable.
- isGlobal: Controls whether the index group appears in the Global Search. Default is
true. - indexRecordAlias: Database alias to use for data retrieval in
queryandsubProcess. - indexGlobalTags: If enabled, global hashtags of a record are indexed. Default is
true. - query: Main process providing the data for the indexer.
- subProcess: Optional process to modify or enrich the data from
query(e.g., from external sources). - affectedTables: List of database tables to monitor. If data changes in one of this tables, an index update is triggered.
- affectedIds: Process to determine IDs of changed datasets for incremental indexing. If not set, a full index run is performed.
tip
In many cases, the result of this process ist the IDvalue of the changed dataset
result.object([vars.get("$local.idvalue")]);
READ_ONLY
Deprecated: This mode is no longer recommended for use and is only documented for legacy purposes. It was formerly used to merge results from existing index groups and apply a search pattern, but its functionality is now better handled by Consumer and JDito.
- searchIndexGroups: Lets you select existing index groups to include in the merged search.
Processes
Processes
The following processes are defined within an IndexRecordContainer to manage search behavior and data preparation.
patternExtensionProcess
This process allows you to append hidden search criteria to the user’s search pattern. The user remains unaware of this logic. Patterns must follow Lucene syntax.
Example: Restrict results to a publishing level if the user has the role PROJECT_Support.
import { logging, result, db, vars, tools } from "@aditosoftware/jdito-types";
if (tools.hasRole(vars.get("$sys.user"), "PROJECT_Support")) {
result.string(
"( +_index_group_:KNOWLEDGE_KNOWLEDGEBASE + (publish_value:2) ) OR -_index_group_:KNOWLEDGE_KNOWLEDGEBASE"
);
}
query
This is the main process for supplying data to the indexer. It must return a two-dimensional array whose structure matches the indexFieldMappings.
- The first three columns are mandatory:
#UID,#TITLE,#DESCRIPTION - Additional fields can follow in any order as long as it matches
indexFieldMappings - Supports concatenation of fields for complex titles or descriptions
- Can fetch data from SQL, web services, or custom logic
Simplified example:
result.object([
["UID1", "TITLE1", "DESCRIPTION1", "A", "B"],
["UID2", "TITLE2", "DESCRIPTION2", "C", "D"]
]);
- Add an
ORDER BYclause on the UID if multi-valued fields are used - Use
$local.idvaluein combination withaffectedIdsfor incremental indexing
subProcess
This optional process modifies each dataset returned by query, individually. It receives:
$local.idvalue: the ID of the current record$local.data: a one-dimensional array representing the current record
You can transform values, enrich with external logic, or recalculate fields.
This process is executed once per dataset. Ensure minimal execution time and avoid unnecessary operations to prevent performance degradation during indexing.
Simple example:
import { vars, result } from "@aditosoftware/jdito-types";
let data = vars.get("$local.data");
data[2] += "_suffix";
result.object(data);
affectedIds
This process determines which datasets changed and must be reindexed during incremental runs. It must return an array of UID values.
You get:
$local.table: name of the modified table$local.idvalue: changed record ID
Example:
import { vars, result, newSelect } from "@aditosoftware/jdito-types";
let table = vars.get("$local.table");
let id = vars.get("$local.idvalue");
let ids;
switch (table) {
case "KNOWLEDGEMANAGEMENT":
ids = [id];
break;
case "KNOWLEDGETAGLINK":
ids = newSelect("KNOWLEDGEMANAGEMENT_ID")
.from("KNOWLEDGETAGLINK")
.where("KNOWLEDGETAGLINK.KNOWLEDGETAGLINKID", id)
.arrayColumn();
break;
}
if (ids) result.object(ids);
Subgroups
Subgroups allow you to categorize search results within an IndexRecordContainer. Each result entry can be assigned a subgroup by setting a string value in the special index field #SUB_GROUP.
The value for #SUB_GROUP must be provided at the exact position specified in indexFieldMappings. You can set this value either directly in the query result or dynamically in the subProcess.
If you choose to set the subgroup dynamically in subProcess, the corresponding field position must still be reserved in the query result. This means you must include a placeholder column (e.g., an empty string) at the position mapped to #SUB_GROUP.
Example: reserving the #SUB_GROUP column in the query
import { vars, result, newSelect } from "@aditosoftware/jdito-types";
// The '' ensures that the column for #SUB_GROUP exists in the correct position.
result.object(newSelect("A, B, C, ''").from("TABLE"));
Filter Extensions
Filter extensions allow you to define additional filters that are automatically applied by the Global Search when executing queries against the IndexRecordContainer.
These filters are defined in the FilterExtensions node of the IndexRecordContainer and support conditions based on user roles, entity fields, or other context-sensitive logic.
If you use JDito to execute index searches, you can convert an existing filter definition (e.g., from a user-defined filter dialog) into a valid Lucene filter expression using the helper method indexsearch.convertFilterToPattern().
Refer to the JSDoc of indexsearch.convertFilterToPattern() for a detailed explanation of supported filters and examples.
Index recordfield mappings
Like other RecordContainers, the IndexRecordContainer defines recordfield mappings. These appear as sub-nodes of the container in the Navigator.
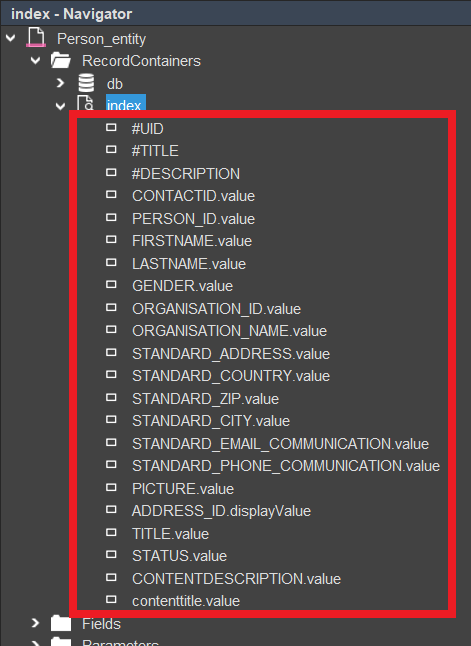 Recordfield mappings of the IndexRecordContainer for Person_entity (module contact)
Recordfield mappings of the IndexRecordContainer for Person_entity (module contact)
Each recordfield mapping defines how one field is written to the index. Besides assigning a name and selecting the correct field from the result, you must configure the appropriate indexFieldType and—if applicable—additional options like boosting, language handling, or phonetic processing.
Most properties of a recordfield mapping are documented inline in the property editor. Key settings include:
fieldName: Must match the label used inindexFieldMappingsindexFieldType: Defines how the field is tokenized and interpreted during indexing and querying. See Appendix A for type details.isMultiValued: Set totrueif the field can occur multiple times per dataset. This is required for correct indexing and must be combined with a correctly orderedqueryresult (ordered by UID).isBoosted: Optional boolean factor to influence ranking for this field.additionalFieldNameAliases: Allows the field to be searched via alternative names in Lucene queries.
IndexFieldType
Each recordfield mapping must define an index field type, unless the property systemField is set. The field type determines how values are stored, tokenized, and queried in the index.
For a complete and up-to-date list of available types, including technical parameters, refer to Appendix A: Index Field Types.
The following summaries describe typical use cases and behaviors.
ADDRESS
Optimized for addresses (country, city, ZIP, street). Applies phonetic normalization and soundex logic. Use with caution for values containing numbers—consider TEXT_NO_STOPWORDS instead if precision is important.
BOOLEAN
Accepts true or false. Values like 1, t, or T are interpreted as true; all others as false.
COMMUNICATION
Generic type for phone numbers, email addresses, or URLs. Use TELEPHONE or EMAIL for more targeted behavior.
DATE
For date or timestamp values in millisecond resolution.
DOUBLE / INTEGER / LONG
Numeric field types for floating-point values (DOUBLE), 32-bit integers (INTEGER), and 64-bit integers (LONG).
EMAIL
Specialized for email addresses. Normalizes and tokenizes common structures like user@domain.
HTML
Internally uses TEXT_NO_STOPWORDS, but removes HTML tags before indexing if the source field type is HTML or FILE. Tag stripping is handled by ADITO core logic.
LOCATION
For spatial search using coordinates in the format "lat, lon".
PHONETIC_NAME
Phonetic search for personal names, tolerant to spelling variations (e.g., "Meier", "Mayer").
PROPER_NAME
For company or organization names. Applies basic phonetic transformation. Avoid use if values are numeric or contain alphanumeric codes.
STRING
For short, fixed identifiers (e.g., UIDs, codes). No tokenization. Only exact-match search supported. Use DISTINCT_CODE for normalized variants.
TELEPHONE
Optimized for phone numbers. Supports normalization of area codes, special characters, and country prefixes.
TEXT
Standard type for general text. Applies lowercasing, normalization, word splitting, and stopword filtering. Not suitable if stopwords must be preserved.
TEXT_NO_STOPWORDS
Like TEXT, but keeps all terms—including stopwords—during indexing and search.
TEXT_PLAIN
Basic text normalization without tokenization. Retains umlauts and special characters. Best for structured labels or keywords.
DISTINCT_CODE
For codes or identifiers like serial numbers or customer IDs. Indexes both original and normalized (punctuation-free) forms for tolerant matching.
AdditionalFieldNameAliases
This property allows you to define alternative names ("aliases") under which the field can be queried via Lucene syntax in the Global Search.
For example, if the field FIRSTNAME is given the alias christianname, users can search it using christianname:Peter.
Aliases are especially useful when:
- the actual field name is technical or unintuitive
- multiple fields should be searchable under a shared term
- external systems or documentation reference different terminology
Multiple fields can share the same alias. In this case, the search term applies to all mapped fields.
Example
The following example shows how the IndexRecordContainer for the Person context is configured to support a Global Search query for a last name like "Smith".
Configuration Overview
Open the Person_entity (module contact) in the Navigator and locate the RecordContainer named index. The key properties are:
-
query:
The title field is composed by concatenatingSALUTATION,FIRSTNAME, andLASTNAMEfrom the tablePERSON, andNAMEfrom the relatedORGANISATION.
The description is assembled using helper functions that retrieve values fromADDRESSandCOMMUNICATIONtables (e.g., address, phone, and email).
All these values are explicitly included in theSELECTclause, and the primary keyCONTACTIDfrom theCONTACTtable is used as#UID. -
affectedTables:
Lists all tables involved in the query:PERSON,CONTACT,ADDRESS,COMMUNICATION, andORGANISATION. -
affectedIds:
A JDito process that determines the impactedCONTACTIDs based on changes in any of the tables mentioned above.
RecordField Configuration
In the sub-nodes of the IndexRecordContainer, each relevant field from the query is mapped with its own fieldName and indexFieldType. For example:
- The field
STANDARD_EMAIL_COMMUNICATIONis configured withindexFieldType = EMAIL - Additionally, it uses the alias
emailviaadditionalFieldNameAliases, allowing Lucene-style queries likeemail:smith@example.com
This setup ensures that a search term like smith will match records where the last name, email address, or associated organization contains that term.